Cloud Computing - From the Lens of a Data Engineer

The advent of the era of cloud computing in the past 10 years has made data storage and processing, leap to a whole different dimension. Previously, the organizations were only looking for ways to store historical data efficiently and safely in the cloud. Now, the perspective has changed. It isn’t just about the storage anymore but the organizations need to make better decisions based on the data.
There has been an evolution from traditional data lake – data warehouse architectures and the organizations are looking for faster and efficient ways in decision making by extracting the value out of the stored information. In this article, we will be having an eagle’s eye view of the current age of cloud computing: from the eyes of a data engineer. We hope that this will give a vision on what an organization expecting to leverage cloud computing to get value out of their data should foresee.
The need for cloud computing
We have come a long way from downloading huge chunks of data from the OLTP to process it in-house. Some organizations do this even today without knowing the risk and the cost behind it. Setting up the infrastructure locally is another major hurdle. The dawn of cloud computing has brought cheaper solutions to everyday problems in data engineering and analytics. The following points justify how cloud computing services help any data-driven business grow:
a) Choice of the Cloud Offering
This is the most crucial step. As the organization grows, spending on services also increases. Hence, the organization should be wise in choosing which cloud offering is right for them. The choice of database services (Self-managed Open-Source databases vs databases offered by the cloud) depends on this. An organization can choose from any of the leaders such as – Amazon Web Services, Azure, Google Cloud, IBM Cloud, etc.
b) Cheaper & Flexible Pricing of Compute Resources, Services & Storage
With the fast adaptability of the cloud offerings, the organizations get access to powerful compute resources at affordable hourly pricing. The cloud services also offer many platforms for the processing, storage, and visualization of the data. Most of them work on the Pay-Per-Use business model. The use of the services is metered and charged only for the period they have been used. The service can also be paused during which no charges will be applied.
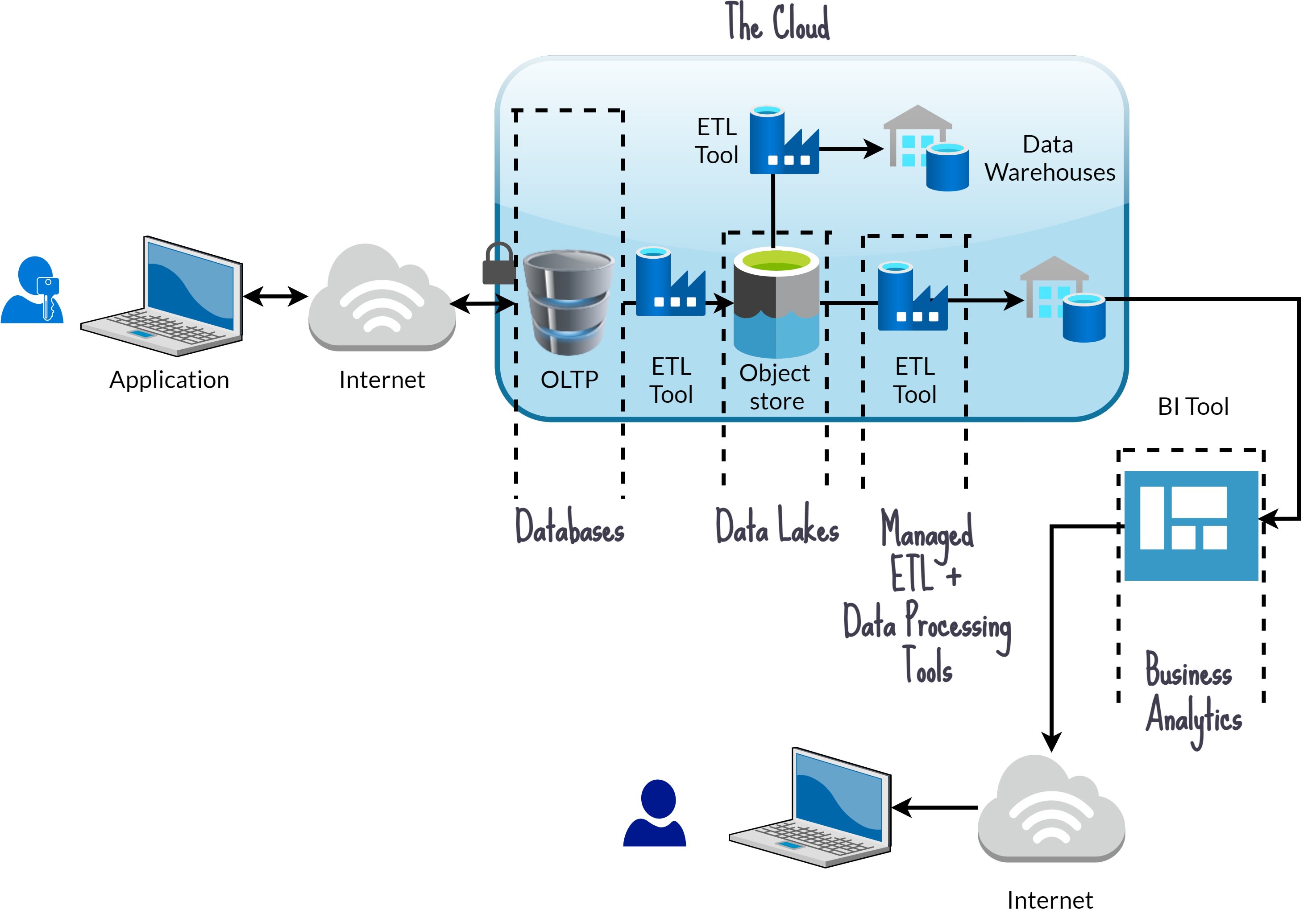
Some of the examples of the PAAS solutions provided by the cloud services include:
| Service Type | Service in AWS | Service in Azure | Service in IBM Cloud |
|---|---|---|---|
| Database Services | RDS (Relational Database Services) | SQL Server | DB2 |
| Managed ETL Services | Glue | ADF (Azure Data Factory) | Cloud Pak for Data |
| Data Processing Tool | EMR (Elastic Map Reduce), Databricks | Databricks | IBM Analytics Engine |
| Business Analytics | Amazon Quicksight | Power BI | Watson Studio |
| Data Lakes | S3 | Blob Storage | Object Storage |
c) Data Security
With an organization’s data residing in its very own cloud infrastructure, it is more secure than in-house storage. There could be numerous reasons for the in-house outages ranging from natural calamities, data breaches to asset thefts. The organization has better control over its data ecosystem when it is on the cloud. There are numerous tools and solutions provided by the cloud service provider. With mechanisms such as OpenID Connect and authentication protocols, Organizations can attach their directory service and associate it to the Identity & Access Management of the cloud service providers to secure their data ecosystem and provide controlled access to the needed individuals through roles and security policies.
d) Improved SLA – Up to 99.9%
This is one of the major factors for the reason to migrate the data to cloud premises. The cloud services provide high availability to the data ecosystem by continuous replication across different data centers situated across regions around the globe. For OLTP systems, mechanisms such as snapshotting, cross-region replication keeps the SLA metric high up to 99.9%. Business-critical deployments need such SLAs to address the high availability of the data ecosystem.
e) From Data to Results – Scalability at Disposal
There could be times when there’s a temporary need for a higher compute throughput or to crunch numbers out of a huge dataset. The organization can bump up the class of clusters from a lower class to a higher class of instances, just to perform the transformations and calculations and post the activity brought down back to the original compute power. All this can be scaled up and down automatically based on the thresholds. The data processing tools and services, that are as part of the infrastructure can help the organization get up and running, rather than setting up the whole architecture. For example, an organization can use Elastic Map Reduce (EMR) to set up their compute resources for data processing, install all the required tools and tune it based on the required throughput (or) opt for the Databricks services, get up and running under 15 minutes.
The Importance of a Sandbox Environment
As mentioned before, analysts don’t have to download the whole datasets locally or even perform the query processing from their local machines anymore. Secure self-service analytics has been made possible by cloud computing solutions. Organizations set up a centralized data lake, rich with the raw data, and the data processing tools or services are set up with periodic jobs to perform the transformation and loading activities to the data warehouses. In some cases, these data warehouses are directly used in Business Analytics by creating the KPIs and aggregations and visualizing them in the dashboards. For higher throughput, performance and to aggregate from multiple data sources, the organizations create data models on top of the data from data warehouses to create the aggregations and KPIs. All the aforementioned activities can be performed inside the sandbox hosted on the cloud rather than bringing the data in-house.
Conclusion
In this article, we have gained an understanding of how and why cloud computing can be utilized to build a data ecosystem of the organization. We have also pointed out the good practices that can be implemented for creating a better and safer self-serve data environment.